Bijna elk dev team heeft tegenwoordig AI in de toolstack. Maar weinig teams weten die lawine aan AI-code om te zetten in meer features in productie. Code produceren is het probleem niet meer. Begrijpen wat er geproduceerd is, dat is de uitdaging.
Voor wie? De tech lead of senior developer die ziet dat het team blijft hangen in AI-experimenten en de controle terug wil over de codebase.
De release van vorige maand: 57 PR's, 446 commits, 568 bestanden. Grotendeels AI-gegenereerd. 4 microservices, 1 frontend en 1 website die tegelijk live moeten. Alles compileert. De tests slagen.
De realiteit: durf je te releasen? We snappen wat de code doet, maar we doorgronden niet meer waarom het klopt.
Dat gevoel is de geboorte van Verification Debt. Als je team meer genereert dan ze kunnen reviewen, bouw je een schuld op die lastiger te herkennen is dan technical debt.
Wat er bij mij is veranderd
Na 20+ jaar development had ik mijn manier van werken. Lange tijd gebruikte ik code-analyse tools en later GitHub Copilot voor autocomplete en de ingebouwde chatfunctie in mijn editor. Handig. Mijn output bleef hetzelfde.
Tot ik in augustus 2025 overstapte naar Claude Code in de CLI. Geen slimmere autocomplete meer in mijn editor. Dit was een assistent die zelfstandig in mijn codebase werkt: code genereren, tests draaien, refactoren. Ik specificeer, review en stuur bij. De AI doet het werk.
De eerste week was ik enorm enthousiast. De tweede week onrustig: als dit zo snel gaat, wat is mijn rol dan nog? De derde week kreeg ik door dat er meer fouten in zaten dan ik op het eerste gezicht had gezien. Dat was het moment dat ik begreep: sneller coderen lost niks op als je niet scherper leert reviewen.
Dat veranderde alles. De tool zelf was het niet. Het zat in wat die tool van mij vroeg. Ik codeer minder, ik specificeer meer. De AI voert uit, runt de tests en komt terug met het resultaat. Mijn werk is verschoven van ‘hoe codeer ik dit?’ naar ‘wat wil ik, en is dit wat ik bedoelde?’ Hoe scherper de spec, hoe minder review-rondes. Dát is waar de echte versnelling zit.
En precies daar lopen teams vast. Het genereren gaat prima. Het regisseren is het probleem.
Experimenteren vs adopteren
Het verschil klinkt klein, maar het is groot:
Experimenteren
Tool gebruiken. Proberen. Nog een keer. De workflow blijft hetzelfde. Je krijgt meer code, maar niet meer grip erop.
Adopteren
Tool integreren. Workflow aanpassen. Snelheid mét controle.
Veel teams blijven hangen bij experimenteren. En dat kost iets.
De cijfers bevestigen dat beeld. Bijna elke developer gebruikt AI [1], maar minder dan de helft reviewt altijd voor commit [2], en PRs worden steeds groter [3]. Dat hoeft niet per se door AI te komen, en grotere PRs zijn niet per definitie slechter. Maar het patroon is herkenbaar: AI maakt het verleidelijk om meer code te genereren dan je kunt reviewen, en die code bevat meer issues [4]. Dat creëert review-druk.
Kevin Browne noemt dit patroon Verification Debt [5]: de kloof tussen hoe snel AI output genereert en hoe snel mensen die kunnen verifiëren. Hij beschrijft het als een breed maatschappelijk probleem, van academische papers tot medische diagnoses. Werner Vogels past het toe op software development [6], en daar zoom ik in dit artikel op in.
Bij Technical Debt weet je wat je inlevert: je kiest bewust voor snelheid boven kwaliteit. Die schuld ken je. Bij Verification Debt is dat anders. De code ziet er goed uit, compileert, en de tests slagen. Maar niemand heeft elke regel doorgrond.
Technical Debt is een lening die je bewust aangaat. Je weet wat je terugbetaalt.
Verification Debt is een contract dat je tekent zonder de kleine lettertjes te lezen.
| Technical Debt | Verification Debt | |
|---|---|---|
| Oorzaak | Bewuste shortcuts voor snelheid | AI kan sneller genereren dan het team kan begrijpen |
| Zichtbaarheid | Vaak bekend bij het team | Verborgen achter groene tests en nette code |
| Manifestatie | Rommelige, fragiele code die wijzigingen en soms performance vertraagt | Code die doet wat hij zegt, maar niet wat je bedoelt |
| Gevolg | Hogere onderhoudskosten en trage feature-delivery | Onvoorspelbare incidenten en verlies van domeinkennis |
| Oplossing | Refactoring sprints | Beheersen met scherpe specs, Fundering (context-files) & Regie |
En wat je niet begrijpt, dat betaal je terug in reviews, bugs en herstelwerk. En met elke regel die niemand doorgrondt, verdampt de domeinkennis die je nodig hebt om het systeem over twee jaar nog te kunnen aanpassen. Het zware werk verschuift van coderen naar reviewen.
Dat is wennen. Ik zat ineens de hele dag code te lezen die ik niet had geschreven. Het geeft een flow, maar ik mis soms het zelf coderen: een uur in een probleem duiken en puzzelen tot het opgelost is. Je identiteit als developer zat in dat coderen. Niet in het beoordelen ervan. Eerlijk: het voelt alsof je vakmanschap minder waard wordt. Maar juist die jarenlange ervaring maakt je de beste reviewer van AI-code. Vakmanschap verdwijnt niet. Het wordt anders ingezet.
Vakmanschap verdwijnt niet. Het wordt anders ingezet.
Waarom is AI-snelheid een risico?
AI-snelheid zonder guardrails (kaders die bepalen hoe de AI werkt) leidt tot drie gevaren:
Codebase-fragmentatie
Zonder gedeelde context-files gaat elke dev met z’n AI een eigen kant op. Elke PR ziet er anders uit. Patronen, naamgeving, structuur: niets is meer consistent.
Review-moeras
AI genereert sneller en meer. PR’s worden groter en bevatten meer issues [4]. En het schaalt: stel dat elke developer 30% meer output levert. Je krijgt niet 30% meer resultaat. Je krijgt 30% meer PR’s om te reviewen. Je PR-lijst puilt uit, de druk om snel te approven groeit mee, en niemand wil onbegrepen AI-code reviewen.
Vertrouwensgat
Er komt code bij die niemand heeft geschreven en niemand volledig begrijpt. Bugs duiken op waar je ze niet verwacht. En security-fouten zijn het verraderlijkst: een ontbrekend [Authorize] attribuut crasht niet, het opent een deur. Wie is eigenaar van code die niemand heeft geschreven? Zonder antwoord op die vraag daalt het vertrouwen snel.
Het moeilijkste deel is niet de techniek
Wat gebeurt er als je zelf al verder bent met AI dan de rest van het team? Er ontstaat frictie. Niet over de tooling. Over het tempo. Jij ziet de mogelijkheden. Je team ziet alleen enorme PR's en denkt: moet dit echt zo?
Ik heb dat zelf meegemaakt: een grote AI-gegenereerde PR leidde tot een stevige discussie in het team. Ik voelde me aangevallen, mijn enthousiasme de grond in geboord. Achteraf terecht. Het liet zien hoe snel frictie ontstaat als je niet samen optrekt.
Hoe neem je ze mee zonder te gaan duwen? En wie bepaalt eigenlijk het tempo?
Het eerlijke antwoord: een senior die AI wantrouwt heeft vaak gelijk. AI-output is niet betrouwbaar genoeg om blind te vertrouwen. Dat is geen weerstand, dat is vakmanschap. DORA noemt dit “trust but verify”: gebruiken én kritisch blijven tegelijk. Dat is volwassen adoptie.
Verschuif het gesprek van “gebruik het” naar “hoe zet je het effectief in?” Laat die senior de kwaliteitsnormen bepalen voor AI-output. Niet “gebruik het nu”, maar “onder welke voorwaarden zou jij dit accepteren?” Dat verandert het gesprek van dwang naar eigenaarschap. De senior bepaalt de kaders, de AI werkt erbinnen.
Niet “gebruik het nu”, maar “onder welke voorwaarden zou jij dit accepteren?”
Weerstand is normaal. Het is een signaal dat er iets op het spel staat. Gelijk optrekken is belangrijker dan snel vooruit, en als iemand niet meedoet: vraag waarom. Hoe diep die weerstand zit, werk ik uit in AI-weerstand in je dev-team: waarom de discussie muurvast zit: drie soorten weerstand, en wat per soort werkt.
Hoe pak je dat aan?
Er bestaan uitgebreide modellen voor AI in software teams. ELEKS AI-SDLC vertelt je waar je staat (van traditional tot AI-native). DORA laat zien dat AI versterkt wat er al is: sterke teams worden sterker, zwakke teams worden zwakker. AI vergroot throughput, maar ook instabiliteit.
Wat volgt is een praktische workflow, gebouwd vanuit mijn eigen ervaring, 20 jaar samenwerken in dev teams en gesprekken met developers die AI in teamverband gebruiken.
Neem dit model niet blind over
Het is een werkmodel, nog niet breed gevalideerd. Gebruik wat past bij jullie situatie. Mis ik iets? Denk mee.
Wie zijn tests op orde heeft, zijn architectuur begrijpt en scherpe prompts schrijft, is al halverwege. Dit model is geen extra proces bovenop je werk. Het is een manier om als team af te spreken hoe je met AI werkt.
Solo developer? Dan heb je dit waarschijnlijk niet nodig. Team van vijf? Dan is de vraag niet meer “kan ik dit?” maar “doen we dit samen op dezelfde manier?”
Wacht niet tot je alle stappen hebt uitgewerkt. Eén senior die op maandagochtend een halfuur met het team zit en twee regels aan de context-file toevoegt, is al genoeg om te starten. De vijf stappen hieronder zijn geen voorwaarde om te beginnen. Ze zijn een kaart voor als je verder wilt.
De aanpak werkt op twee niveaus. Per sprint doorloop je vijf stappen, bewust gedoseerd. Niet te snel, zodat ieder teamlid bijblijft: de enthousiaste junior en de terughoudende senior. Per dag werkt elke developer in een eigen ritme van specificeren, delegeren, reviewen en bijsturen.
De vijf stappen
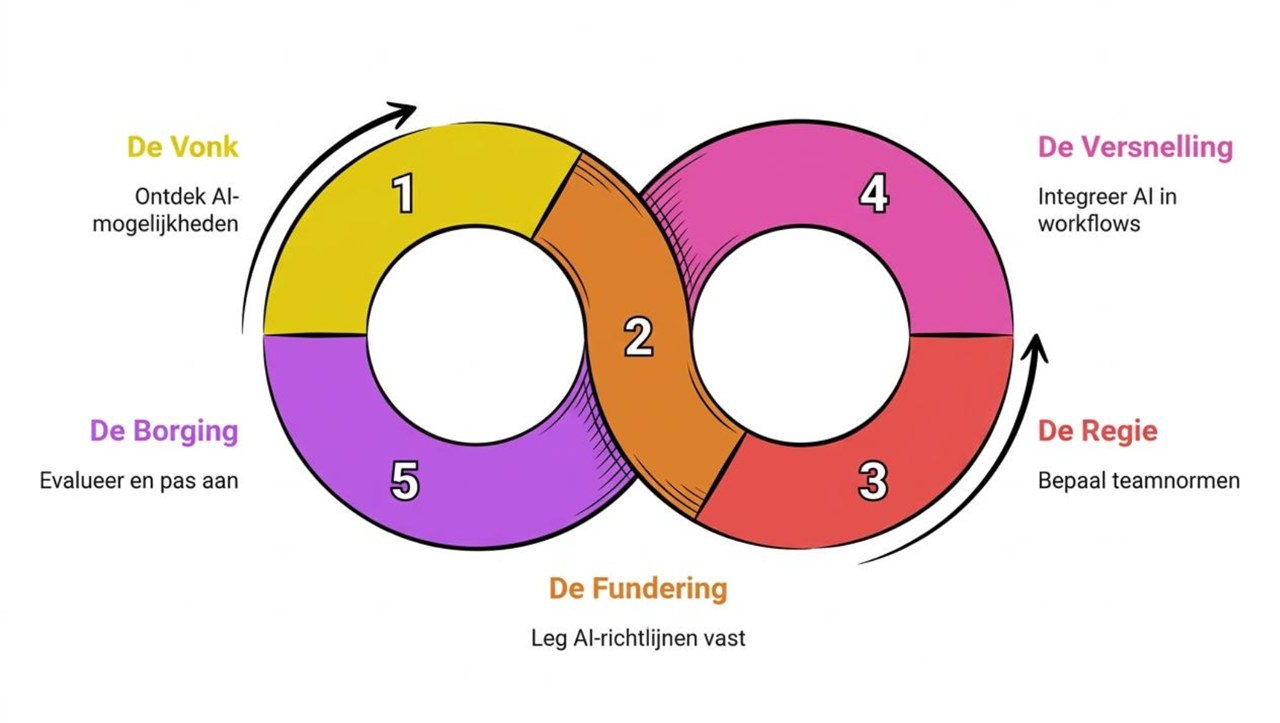
De volgorde is bewust: elke keer dat je een nieuwe AI-tool of mogelijkheid introduceert, zorg je dat Fundering en Regie staan voordat je versnelt. De eerste ronde is de zwaarste. Daarna draai je lichtere rondes. Vertrouwen groeit sneller door kleine successen dan door in één keer alles aan de AI te delegeren.
De Vonk
De eerste keer ontdek je wat AI kan in jouw codebase. In volgende rondes is De Vonk het moment waarop je een nieuwe tool, plugin of mogelijkheid verkent. Niet tien tools tegelijk, maar een kwartier demo bij de start van de sprint. Genoeg om bij te blijven, niet genoeg om je team gek te maken. Bij De Vonk bepaal je met elkaar hoe groot de volgende stap is: een kleine plugin, of een fundamenteel andere manier van werken. Dat tempo kies je samen. Maar enthousiasme zonder kaders leidt tot chaos. Daarom volgt direct:
De Fundering (kaders voor de AI)
In de eerste ronde leg je vast hoe de code eruitziet. Context-files voor je AI-tool (CLAUDE.md, .cursorrules, copilot-instructions.md), code guidelines, architectuurkeuzes. Guardrails zijn alles wat de AI binnen de lijnen houdt: context-files, pre-commit hooks, CI-linter regels en je test-suite. Zonder tests heeft de AI geen feedbackloop. Lage test coverage + AI = code die je niet naar productie durft te brengen.
Let op: als een team met AI aan de slag gaat, daalt de kwaliteit eerst. Je genereert sneller, maar de fouten nemen toe. Dat moet je verderop in het proces opvangen: scherpere PR reviews, meer automatische tests, browser tests, en strengere acceptatie.
Juist daarom niet te grote stappen zetten. Hier haken veel teams af. Het voelt als overhead. Maar context-files zijn geen documentatie die niemand leest: je merkt direct als ze verouderd zijn, want de AI-output wordt slechter. Dat is een ingebouwde feedbackloop. En zonder die investering genereert je AI sneller rommel dan je kunt opruimen.
Bij elke volgende ronde van de cyclus scherp je De Fundering aan: nieuwe richtlijnen, betere tests, strengere guardrails.
Hoe bouw je zo’n context-file op? In Hoe bouw je context op met Claude Code? laat ik stap voor stap zien hoe je CLAUDE.md opbouwt, splitst naar rules-bestanden en onderhoudt.
De Regie (normen voor het team)
In de eerste ronde bepaalt het team de normen. Vóór je gaat versnellen met AI. “Wij stoppen met het reviewen van code-conventies. Die horen in de context-file. Reviews gaan over architectuur en logica.” Hier ontstaan discussies: wat is een conventie en wat is een architectuurkeuze? Naamgeving is een conventie. Maar “altijd via de repository-laag” is een architectuurkeuze die eruitziet als een conventie. Die grens trekken is de regie.
En het geeft de senior zijn vakmanschap terug: geen discussies meer over naamgeving, maar focus op de robuustheid en schaalbaarheid van het systeem. AI genereert code die werkt voor nu, maar een senior ziet of het ook werkt bij 10x meer gebruikers. In volgende rondes scherp je de normen aan: wat werkte, wat niet, welke afspraken moeten strakker? Zonder Regie wordt De Versnelling rommelig.
De Versnelling (AI in je workflow)
In De Vonk heb je verkend wat er mogelijk is. Nu voer je het uit. De AI werkt zelfstandig in de codebase, runt tests, doet voorstellen. Hoeveel dat is hangt af van hoe sterk je Fundering en Regie staan. Die kaders houden je veilig.
AI nodigt uit tot grote, monolithische wijzigingen. Stuur daar bewust tegenin. Laat de AI taken opknippen in kleine, reviewbare PR's. Wie grote brokken AI-code over de schutting gooit, respecteert de tijd van de reviewer niet.
Hoe scherper de spec, hoe minder je achteraf hoeft te reviewen. Sneller typen levert niks op. De versnelling zit in kortere doorlooptijden. Minder wachttijd, meer parallelle taken, snellere iteraties. En naarmate je regie sterker wordt, kun je ook AI-review tooling inzetten voor de eerste check. De mens blijft eindverantwoordelijk.
De Borging
Zonder meten weet je niet of je vooruitgaat. Begin met een nulmeting vóór je AI inzet, zodat je weet of het daadwerkelijk verschil maakt en niet alleen sneller vóélt. Meet iedere sprint vier dingen:
- Doorlooptijd per PR: stijgt die terwijl je meer genereert? Dan komen de reviews niet mee.
- Revert-rate en post-review bugs: hoe vaak draai je code terug, en hoeveel bugs glippen door de review? Een stijging in het begin is normaal. Maar als die na een paar sprints niet daalt, groeit je Fundering of Regie niet mee.
- PR-omvang: groeiende PR's zijn een early warning. Hoe groter de PR, hoe lastiger de review, hoe meer er doorheen glipt. Als een PR te groot wordt voor een mens om in 15 minuten te doorgronden, groeit de Verification Debt sneller dan je kunt aflossen.
- Velocity: levert het team per sprint meer story points op? Belangrijk: blijf schatten op complexiteit met een referentiestory, niet in uren. Als je de schattingsmethode aanpast omdat AI “het makkelijker maakt”, vergelijk je appels met peren en zie je het echte verschil niet. Let op: als de velocity stijgt maar de revert-rate en bugs meestijgen, meet je schijnproductiviteit.
Geen dashboard nodig. Een korte check in de retro is genoeg.
Tip: laat AI je Git-historie analyseren. Via de Git- en GitHub API kun je reverts tellen, PR-omvang meten en doorlooptijd per PR berekenen. Een paar prompts en je hebt deze metrics.
Waar let je op? Als de doorlooptijd per PR stijgt terwijl de output gelijk blijft, groeit je Verification Debt. De echte test: gaat de snelheid omhoog zonder dat de kwaliteit daalt?
Zijn de richtlijnen nog up-to-date? Werken de afspraken nog? Dit is waar het vaak verslapt. Zonder evaluatie sluipt de luiheid erin. Maar als je het wel doet, voedt elke retro de volgende ronde van de cyclus. Bij de start van een nieuwe sprint is er ruimte voor De Vonk: een korte demo van een nieuwe AI-tool of mogelijkheid. Zo blijft de cyclus draaien.
Wie doet wat?
De cyclus draait niet vanzelf. Vier rollen houden het in beweging. Dit zijn petten, geen functies. In een klein team draagt één persoon er meerdere.
- De senior als gatekeeper: een senior die zich een veredelde linter-robot voelt, haakt af. Terecht. Overtuigen werkt hier niet. De kunst zit in het herdefiniëren van de rol. De senior verschuift van codeur naar de persoon die bepaalt hoe er gebouwd wordt: hij reviewt op architectuur en logica, niet op conventies. Niemand kent de codebase beter. Dat geeft hem grip op de AI-output, in plaats van het gevoel dat AI zijn rol overneemt.
- De junior als leerling: AI versnelt het coderen, maar vertraagt vaak het leren. Een junior moet vlieguren maken in het zelf coderen om de intuïtie te ontwikkelen die nodig is voor een kritische review. Zonder die basis wordt hij een passief doorgeefluik van AI-output, en groeit de Verification Debt met elke PR. Dat betekent niet dat juniors geen AI mogen gebruiken. De uitdaging: laat ze eerst zelf nadenken over de oplossing, en gebruik AI dan als sparringpartner. Laat de AI uitleggen in plaats van code genereren. Zo wordt AI een tutor die het denkwerk aanscherpt. Geen vervanger die het overneemt. DORA waarschuwt hier ook voor: als AI het hands-on werk overneemt, missen juniors de kans om ongeschreven kennis op te bouwen die je alleen leert door samen te bouwen.
Concrete aanpak voor juniors: laat ze met AI eerst tests schrijven vóór de code (TDD-stijl). Zo worden ze gedwongen de logica eerst zelf te doorgronden. De AI helpt formuleren, maar de junior bepaalt wát er getest wordt. Dat is het verschil tussen begrijpen en accepteren.
- De champion: de collega die het meest enthousiast is over AI en het voordoet. Niet de enige die AI gebruikt. Wel degene die pilots draait, betere workflows deelt en collega’s meeneemt. Geen trainer en geen manager, gewoon een peer die vertrouwd wordt. Dit is een vaste deeltaak, geen aparte functie.
- De tuinman: AI introduceert patronen die niet bij je architectuur passen. Zonder iemand die dat signaleert, verspreidt het zich als onkruid door je codebase. De tuinman voorkomt dat door de kaders en richtlijnen bij te houden. Bestaande vervuiling opruimen is teamwerk in de sprint. Net als je CI-pipeline: niemand heeft dat als fulltimebaan, maar als niemand het doet, loopt alles vast. Wissel deze rol regelmatig, zodat het niet op één persoon blijft hangen.
Bij elke nieuwe ronde pakt ieder vanuit zijn rol op wat nodig is: de gatekeeper scherpt de review-normen aan, de tuinman werkt de richtlijnen bij, de champion laat de nieuwe workflow zien. Maar dit werkt alleen als het hele team betrokken is bij de beslissingen. Afspraken die van bovenaf komen landen niet. Beslis samen over de kaders, dan ontstaat draagvlak en eigenaarschap.
Het snelle ritme: elke dag
Naast deze cyclus per sprint draait er een kleiner vliegwiel. Dit is hoe je dagelijks met AI werkt:

Dit ritme draait continu. De sleutel zit in de eerste stap: hoe scherper je specificeert, hoe minder je hoeft bij te sturen. Specificeren wordt steeds preciezer naarmate je Fundering beter staat. Reviewen wordt makkelijker naarmate je Regie klopt. En bijsturen voedt De Borging. Hoe ik dat concreet zelf toepas beschrijf ik in mijn artikel over mijn dagelijkse workflow.
Voorbeeld uit de praktijk
De AI genereert een service die rechtstreeks de database aanroept in plaats van via je repository-laag. Je stuurt bij, maar de volgende keer maakt hij dezelfde fout.
Dat is het moment dat je een regel toevoegt aan je context-file: “gebruik altijd de repository-laag, nooit rechtstreeks de database.” Vanaf dat moment gaat het goed.
Dat is waar de twee niveaus elkaar raken: je reviewt en stuurt bij (het dagelijkse ritme), je scherpt De Fundering aan (de cyclus), en in de retro bespreek je met je team of die aanpassing goed genoeg is (De Borging).
Eén valkuil verdient extra aandacht: controleer niet alleen de code, maar ook de tests. Als de AI code én tests schrijft zonder goede specs, ontstaat schijnzekerheid: tests die groen zijn maar het verkeerde testen. De coverage ziet er goed uit, maar de aannames kloppen niet. Dat is een echokamer. Review of de tests de juiste aannames en edge cases valideren, of dat ze alleen de coverage ophogen.
Wat verandert er en wat levert dit op?
In het begin voelt het tegennatuurlijk: je besteedt meer tijd aan sturen en reviewen dan aan meters maken. Maar naarmate je specs scherper worden en je Fundering staat, kantelt het. De review-last daalt, je specificeert preciezer, en de rest gaat meer vanzelf. De totale output wordt hoger, omdat je delegeert in plaats van zelf te coderen.
Wat er verandert is het dagelijkse werk, de rollen en de vragen die je stelt:
- Je besteedt meer tijd aan specificeren dan aan coderen, en AI helpt je om vage requirements scherper te formuleren
- De review verschuift van “klopt de code?” naar “klopt de intentie?”
- Eenvoudige bugs lost AI zelf op. Complexe bugs worden lastiger: je debugt code die je niet zelf hebt geschreven
- De junior leert via AI als tutor
- De senior gaat van codeur naar regisseur: reviewen op architectuur en logica
Dat klinkt als veel. Neem het stap voor stap. Als de kaders staan en iedereen weet wie wat reviewt, ontstaat het vertrouwen om meer aan de AI te delegeren. Het team dat het meest investeert in de Fundering, durft uiteindelijk het meest te versnellen.
Waarom het niet stopt
AI-adoptie is continu werk: elke sprint scherp je richtlijnen aan en groeit het vertrouwen. Maar zonder onderhoud val je terug:
- Codebase-vervuiling: AI introduceert patronen die niet bij je architectuur passen. Zonder de tuinman sluipen afwijkingen erin die je pas merkt als het te laat is. En wie onderhoudt die code over twee jaar als niemand meer weet waarom het zo is gebouwd? Tegelijk verouderen je context-files: je code verandert, maar de richtlijnen niet. Context-files bijwerken is net zo belangrijk als je tests bijwerken.
- Tooling en workflow veranderen continu: de tools van vandaag zijn niet die van over drie maanden. En nieuwe mogelijkheden vragen om aanpassingen in je workflow. De richting is duidelijk: meer autonomie, meer orchestratie, meer agents die samenwerken. Hoe langer je wacht, hoe groter de achterstand.
- Team-discipline: zonder evaluatie sluipt het blind op “Approve” klikken bij een review erin. De kwaliteit daalt en er glippen meer issues ongezien door de PR.
AI-adoptie is geen optionele plugin. Het is een verandering in mindset. Teams die het gesprek over hoe ze AI inzetten laten liggen, verliezen terrein zonder het te merken.
Waar begin je?
Wil je vandaag beginnen? Maak een context-file aan en los daar één gedeelde frustratie in op. Bijvoorbeeld: “geen business logic in controllers, altijd via een service-laag.” Dat is stap 2. Eén bestand, één regel. Kijk wat er verandert.
Loop je vast bij De Fundering (wat leg je vast?), De Regie (wie doet wat?) of De Borging (hoe meten we kwaliteit?)? Zullen we een uurtje sparren over jullie workflow? Geen zwaar traject, maar een gesprek waarin ik deel wat ik zelf heb geleerd.
En die release PR?
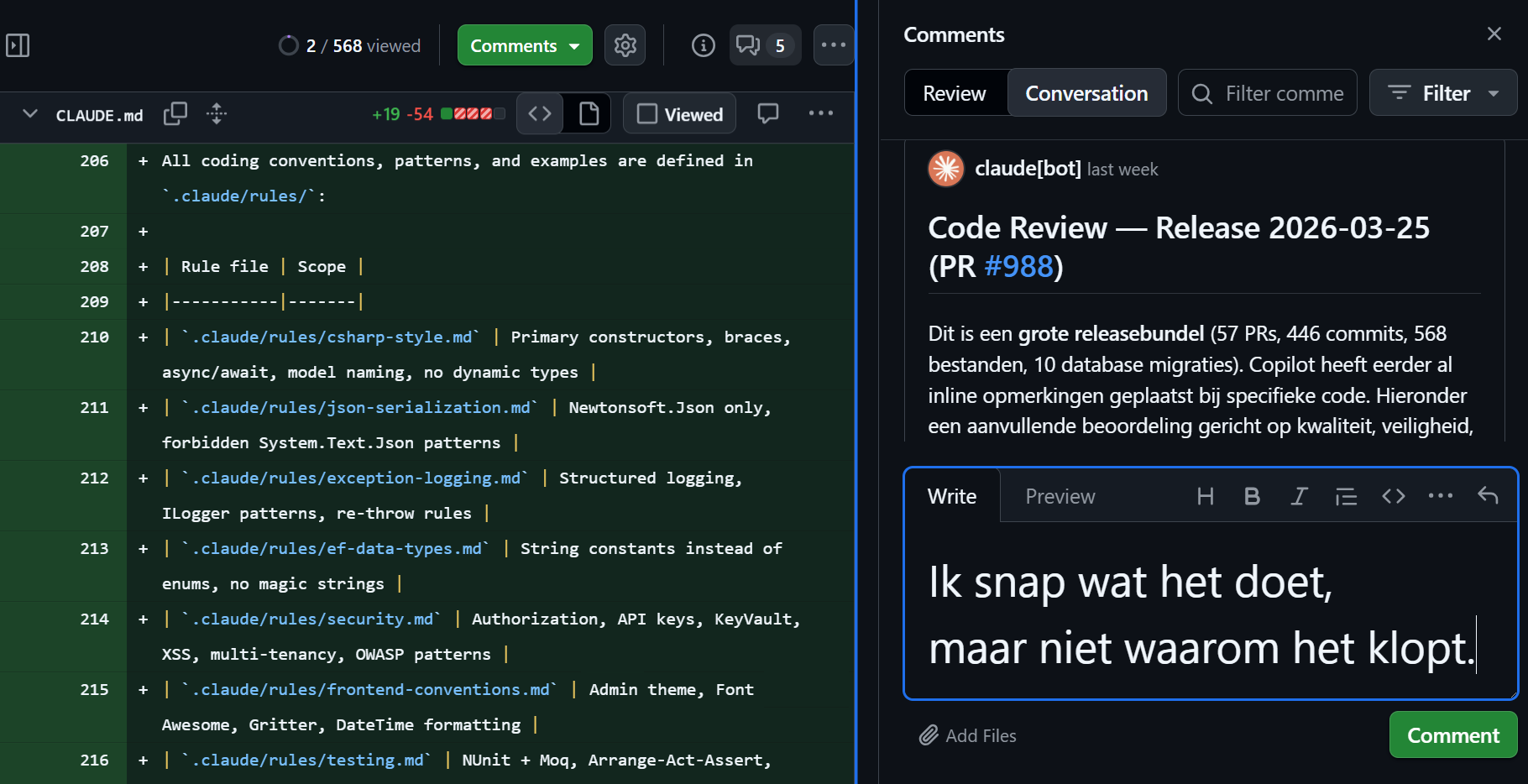
Die release met 57 PR's, 446 commits en 568 bestanden? Ik durfde te releasen. Niet omdat ik alles in één keer had gelezen. Die 57 PR's zijn over weken gemaakt, elk gereviewd op het moment dat ze klaar waren, samen met Claude Code en GitHub Copilot. De release bundelt ze achteraf. En de guardrails waren op orde. 1253 unit tests groen. 8 uur automatische browser tests slaagden na enig rework. En na de release: het aantal post-review bugs viel mee bij de acceptatietest, en de PR-omvang per wijziging bleef klein.
De metrics uit stap 5 bevestigden wat ik voelde: het vertrouwen was opgebouwd, en De Fundering werkte. In de screenshot zie je het contrast: de review-comment “ik snap wat het doet, maar niet waarom het klopt” naast de context-files die de AI sturen. Van angst naar vertrouwen. Dat begint bij De Fundering.
AI maakt output goedkoop. Maar verantwoordelijkheid niet. AI-adoptie is geen project dat je afrondt. Het is een workflow die bepaalt of je team versnelt of vastloopt.
Welke regel zet jij vandaag in je context-file om met meer grip te releasen?